Understand These Four Advanced Concepts To Sound Like A Machine Learning Master
This is a sequel to the post I wrote over a year ago about some basic concepts of machine learning. Sometimes sequels are better like Terminator 2 or Wrath of Kahn, but you can’t enjoy them unless you’ve see the first movie. Go read that post and come back. I’ll wait…
There are many concepts in machine learning that are important to understand in order to be in the know. More importantly, if you’re going to implement AI, sell AI, integrate AI, or write about AI, you might want to brush up on these core, yet advanced, concepts to have a good, strong foundation with which to start from.
After reading this post, your Machine Intelligence Learning Quotient (or MILQ) will increase substantially. Are you ready to get MILQin’?
Precision and Recall
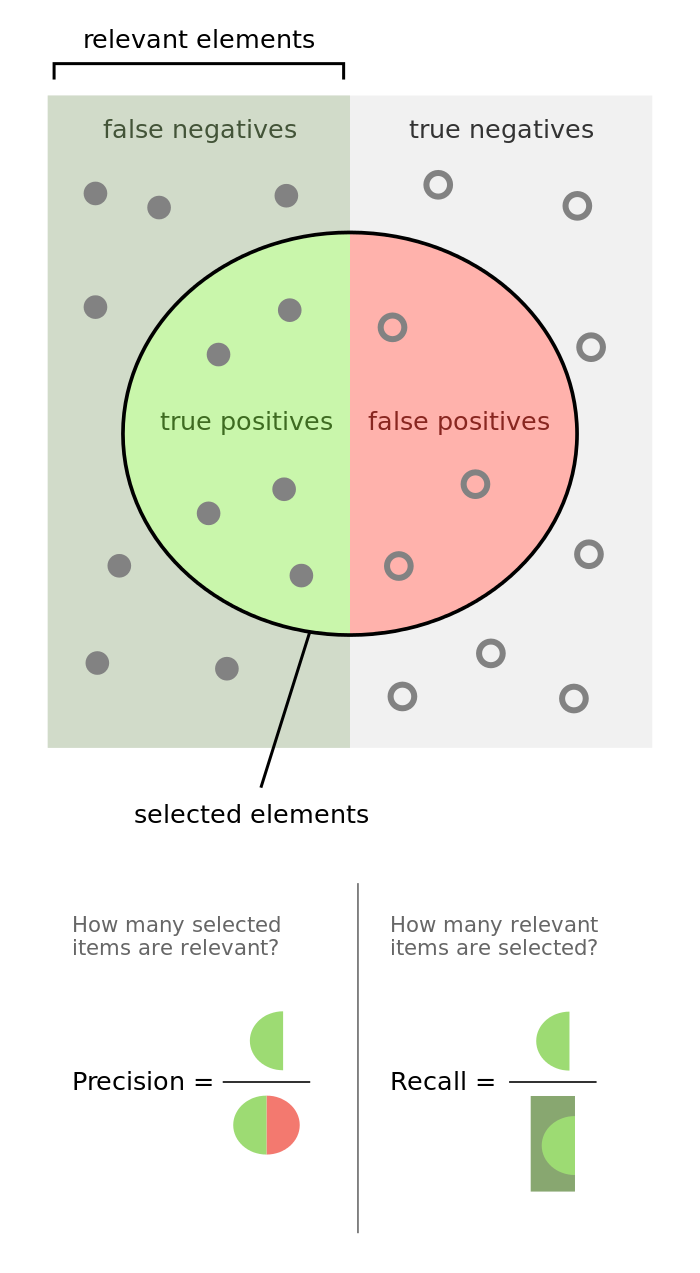
What the living Christ is precision and recall?! Sometimes when you read about precision and recall, they can sound like the exact same thing; “Precision is how often you’re correct and recall is HOW often YOU are correct” — for example. Welp, they’re actually different and unfortunately, important to understanding why a machine learning model works for a use case or not.
Here is probably the third best way I can possibly explain the difference:
Let’s say you are trying to remember something, like how many blue umbrellas you’ve seen in your life. Recall describes how good you are at remembering every time you saw a blue umbrella, at the expense of mistaking some memories of purple umbrellas as well. Let’s say you saw 10 blue umbrellas in your life, and you remembered all 10 of them. But, you also incorrectly remembered 5 additional times that were in fact purple umbrellas (but you remembered them as blue). Your recall is 100% because you remembered every time. Congratulations you weirdo!
Now precision is going to describe what percentage of your memories are actually correct. In the strange example above, out of 15 memories, only 10 were correct. Therefor your precision is about 66%.
So which is more important? Well, it depends on your use case. If you’re using computer vision or deep learning to identify cancer from photos of moles, it might make sense to minimize the number of times you tell a patient they don’t have cancer when they do (false negative), even at the risk of increasing the likelihood of telling people they have cancer when they don’t (false positive).
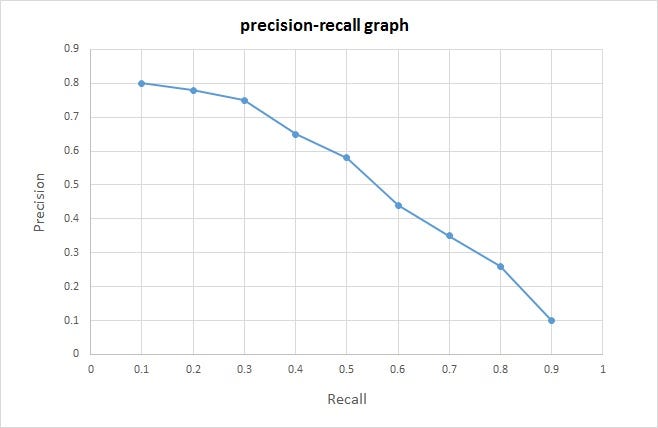
The point is you can’t have both, there is ALWAYS a tradeoff. It just depends which is more important for your use case; getting every true positive at the risk of also getting some false positives? Or making sure as many results are true positive as possible, at the risk of getting more false negatives.
Get it? If you’re still confused, don’t worry, its complicated and hard to remember. But I’m going to move on… ok?
Recognition vs Detection
When you apply machine learning, you get to have some pretty cool tools like face recognition and logo detection. You can also have face detection and logo recognition. WHAT THE HELL. Why?

Let me try to explain this concept by offering some examples of each type:
Face recognition — The input is an image of a face, the machine learning model recognizes the person and returns to you the name of that person.
Face detection — The input is an image of a face, the model returns to you a bounding box around the face it found. It tells you where the face is, but not who it is.
Image recognition — The input is an image, the output is (probably) multiple tags describing that image, such as foggy, car, monochrome, building, landscape etc.
Object detection — The input is a specific image (like a logo) and a general image upon which to do the detection, and the output is bounding boxes around every place that specific image (or logo) appears in an image.
Does that help explain the difference? No? Excellent — we’re on a roll, moving on…
Classification
A lot of good implementations of machine learning are actually classifiers. Is an article fake news or real news, is this image of a leaf a palm frond, a maple leaf or poison oak, is this sentence a run on sentence or not, etc.
Each class is like a choice or a label. You train a machine learning model to put some chunk of input data (like a photo or a news article) into a class. Some models can give you a couple of classes as results and some can only do one class at a time.
The key thing to know is that you have to follow some basic rules when you train a classifier, otherwise it won’t work good (like my grammar checker).
- Your training data has to be balanced. That means you have to have the same number of pictures of cats as you do of dogs. If you try and train a model with uneven classes, it will naturally become more biased towards the class with more examples.
- The model isn’t going to just figure out which examples are wrong. Your training data has to be squeaky clean. If you have some examples of dogs in your cats folder then you’re really screwing yourself over. Go and move those photos to the dogs folder now.
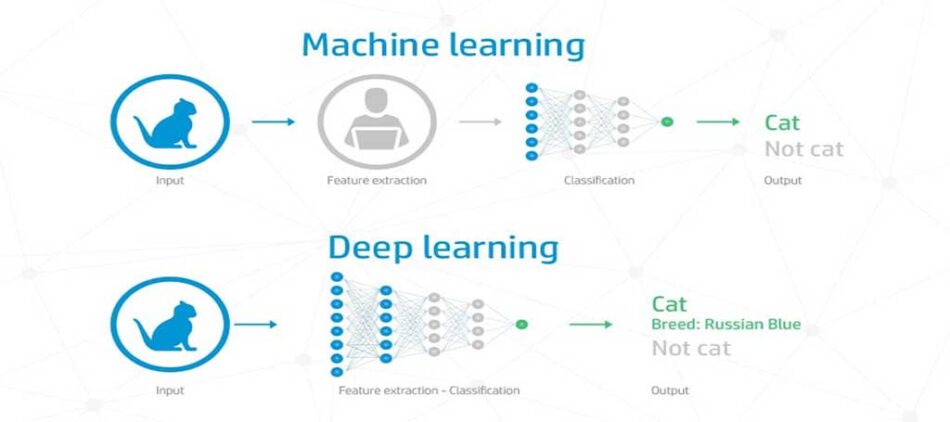
Deep learning

Deep learning sounds awesome, doesn’t it? What could possibly be better than regular learning? I know.. DEEP learning. Well, it turns out that deep learning is awesome, but it comes with a catch. First, let me try and explain what deep learning is.
Most deep learning models are based on artificial neural networks. A neural network is essentially layers upon layers of nodes that are connecting to each other in some goddamned magical way. When you have more than 1 or 2 layers between your input and output layers, you have a deep network! What is really cool is that when you train the network, it somehow figures out how to organize itself to recognize faces (for example). It might assign the first layer into pixel grouping, the second into edge detection, the third into nose understanding, and so on… but it figures it out all by itself. Amazing.
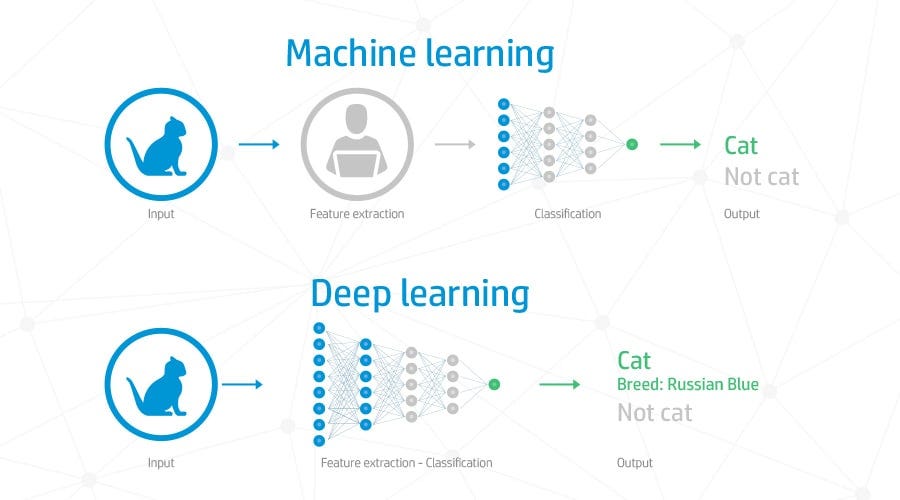
But its not everything. A safe rule of thumb is that when you hear deep learning, it means GPUs. And GPUs are expensive. So you really need to think about your use case. For example, there exists a great face detector out there that does not use deep learning. It is a computer vision filter that has something like a 97% accuracy. There is also a deep learning version of this face detection. The accuracy is incrementally higher BUT it comes at a huge performance cost. You need GPUs! Whereas the computer vision version can run super fast on a single CPU.
So, again, it is a tradeoff.
Well, this concludes your masters course on machine learning.
BYE
![]()
Understand these 4 advanced concepts to sound like a machine learning master was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.